
Portfolio optimization is of central importance to the field of quantitative finance. Under the assumption that returns follow a multivariate normal distribution with known mean and variance, mean-variance optimization, developed by Markowitz (1952), is mathematically the optimal procedure to maximize the risk-adjusted return. However, it has been shown, e.g., by DeMiguel, Garlappi, and Uppal (2007), that out-of-sample performance of optimized portfolios is worse than that of naively constructed ones. The question is why? Do the results break down if the normality assumption is violated? I will show Monte Carlo evidence under heavy tailed distributions that suggest the cause for this strange phenomenon to be a different one.
The actual problem is that, in practice, mean and variance are not known but need to be estimated. Naturally, the sample moments are estimated with some amount of error. Unfortunately, the solution, i.e., the optimal weight vector, to the optimization problem is very sensitive to these estimation errors. The resulting instability of the solution tends to increase with the number of assets in the universe.
To get an intuition why this would happen, imagine 


The solution to the instability problem is to prevent the optimization algorithm from considering unrelated assets as related. This can be done in two ways. Either we reduce noise in the covariance matrix or we allow hedging between instruments only in certain cases where we have a prior believe that future returns will indeed be correlated. For example, the latter solution implies that we may be comfortable asserting that two airlines expose the portfolio to similar kinds of risk, e.g., oil price, political risk, regulatory risk, travel demand, terror risk, etc., and by selling one of them short we may hedge out these risks resulting from holding long the other. In contrast, just because the sample covariance for an airline stock and some other, totally unrelated, stock is slightly positive, this does not mean we should sell short a large chunk of that second stock to hedge out the risks of the airline stock, although the mean-variance optimizer would regard both scenarios the same.
For me, the best way to get a deeper understanding of the subject is to simulate sample paths, where I know the data generating process, and to observe the behavior of different optimization techniques. In the following, I will compare mean-variance optimization based on sample moments with the same based on a noise-reduced covariance matrix using principal component analysis (PCA). To demonstrate the other approach, I will introduce a hierarchical optimization algorithm, where I use the fact that stocks usually cluster into industries. As a lower bound benchmark, I show results for naive equal weighting. We will see that, out-of-sample, portfolios based on the sample covariance matrix underperform this benchmark substantially. The PCA and hierarchical methods, however, perform significantly better. These results are robust to heavy tailed noise distributions as evidenced by simulated Generalized Autoregressive Conditional Heteroscedasticity (GARCH) sample paths.
But first, let’s simulate a bunch of stocks belonging to different industries. Each stock is composed of a deterministic trend 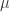
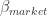

The return of each stock is thus given by

where
is the return of asset
,
is the
th common factor at time
is the factor loading or factor beta of asset
is the asset-specific factor or asset-specific risk,
,
-
.
The 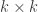
![\boldsymbol{f}_{t}=\left[f_{1 t}, f_{2 t}, \ldots, f_{k t}\right]^{\prime}](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7Bf%7D_%7Bt%7D%3D%5Cleft%5Bf_%7B1+t%7D%2C+f_%7B2+t%7D%2C+%5Cldots%2C+f_%7Bk+t%7D%5Cright%5D%5E%7B%5Cprime%7D&bg=ffffff&fg=303030&s=0&c=20201002)

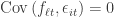

![{\qquad \boldsymbol{\Sigma}_{\boldsymbol{\epsilon}}=\mathrm{Cov}\left(\boldsymbol{\epsilon}_{t}\right)=\left[\begin{array}{cccc}{\sigma_{\epsilon_{1}}^{2}} & {0} & {\cdots} & {0} \\ {0} & {\sigma_{\epsilon_{2}}^{2}} & {\cdots} & {0} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {0} & {0} & {\cdots} & {\sigma_{\epsilon_{N}}^{2}}\end{array}\right]}](https://s0.wp.com/latex.php?latex=%7B%5Cqquad+%5Cboldsymbol%7B%5CSigma%7D_%7B%5Cboldsymbol%7B%5Cepsilon%7D%7D%3D%5Cmathrm%7BCov%7D%5Cleft%28%5Cboldsymbol%7B%5Cepsilon%7D_%7Bt%7D%5Cright%29%3D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D%7B%5Csigma_%7B%5Cepsilon_%7B1%7D%7D%5E%7B2%7D%7D+%26+%7B0%7D+%26+%7B%5Ccdots%7D+%26+%7B0%7D+%5C%5C+%7B0%7D+%26+%7B%5Csigma_%7B%5Cepsilon_%7B2%7D%7D%5E%7B2%7D%7D+%26+%7B%5Ccdots%7D+%26+%7B0%7D+%5C%5C+%7B%5Cvdots%7D+%26+%7B%5Cvdots%7D+%26+%7B%5Cddots%7D+%26+%7B%5Cvdots%7D+%5C%5C+%7B0%7D+%26+%7B0%7D+%26+%7B%5Ccdots%7D+%26+%7B%5Csigma_%7B%5Cepsilon_%7BN%7D%7D%5E%7B2%7D%7D%5Cend%7Barray%7D%5Cright%5D%7D&bg=ffffff&fg=303030&s=0&c=20201002)
The diagonal covariance structure reflects the assumption that all correlation between assets is due to the factors.
Let’s write the factor model as
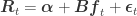
where in the 
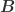
![{\qquad \boldsymbol{B}=\left[\begin{array}{c}{\boldsymbol{\beta}_{1}^{\prime}} \\ {\boldsymbol{\beta}_{2}^{\prime}} \\ {\vdots} \\ {\boldsymbol{\beta}_{N}^{\prime}}\end{array}\right]=\left[\begin{array}{cccc}{\beta_{11}} & {\beta_{12}} & {\cdots} & {\beta_{1 k}} \\ {\beta_{21}} & {\beta_{22}} & {\cdots} & {\beta_{2 k}} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {\beta_{N 1}} & {\beta_{N 2}} & {\cdots} & {\beta_{N k}}\end{array}\right]}](https://s0.wp.com/latex.php?latex=%7B%5Cqquad+%5Cboldsymbol%7BB%7D%3D%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D%7B%5Cboldsymbol%7B%5Cbeta%7D_%7B1%7D%5E%7B%5Cprime%7D%7D+%5C%5C+%7B%5Cboldsymbol%7B%5Cbeta%7D_%7B2%7D%5E%7B%5Cprime%7D%7D+%5C%5C+%7B%5Cvdots%7D+%5C%5C+%7B%5Cboldsymbol%7B%5Cbeta%7D_%7BN%7D%5E%7B%5Cprime%7D%7D%5Cend%7Barray%7D%5Cright%5D%3D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D%7B%5Cbeta_%7B11%7D%7D+%26+%7B%5Cbeta_%7B12%7D%7D+%26+%7B%5Ccdots%7D+%26+%7B%5Cbeta_%7B1+k%7D%7D+%5C%5C+%7B%5Cbeta_%7B21%7D%7D+%26+%7B%5Cbeta_%7B22%7D%7D+%26+%7B%5Ccdots%7D+%26+%7B%5Cbeta_%7B2+k%7D%7D+%5C%5C+%7B%5Cvdots%7D+%26+%7B%5Cvdots%7D+%26+%7B%5Cddots%7D+%26+%7B%5Cvdots%7D+%5C%5C+%7B%5Cbeta_%7BN+1%7D%7D+%26+%7B%5Cbeta_%7BN+2%7D%7D+%26+%7B%5Ccdots%7D+%26+%7B%5Cbeta_%7BN+k%7D%7D%5Cend%7Barray%7D%5Cright%5D%7D&bg=ffffff&fg=303030&s=0&c=20201002)
the ![\boldsymbol{R}_{t}=\left[R_{1 t}, R_{2 t}, \ldots, R_{N t}\right]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7BR%7D_%7Bt%7D%3D%5Cleft%5BR_%7B1+t%7D%2C+R_%7B2+t%7D%2C+%5Cldots%2C+R_%7BN+t%7D%5Cright%5D&bg=ffffff&fg=303030&s=0&c=20201002)

Hence, the variance of the returns of asset

and

respectively. Since the factors are uncorrelated in this simulation, the covariance matrix simplifies to

where 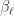

and the covariance between the returns of assets

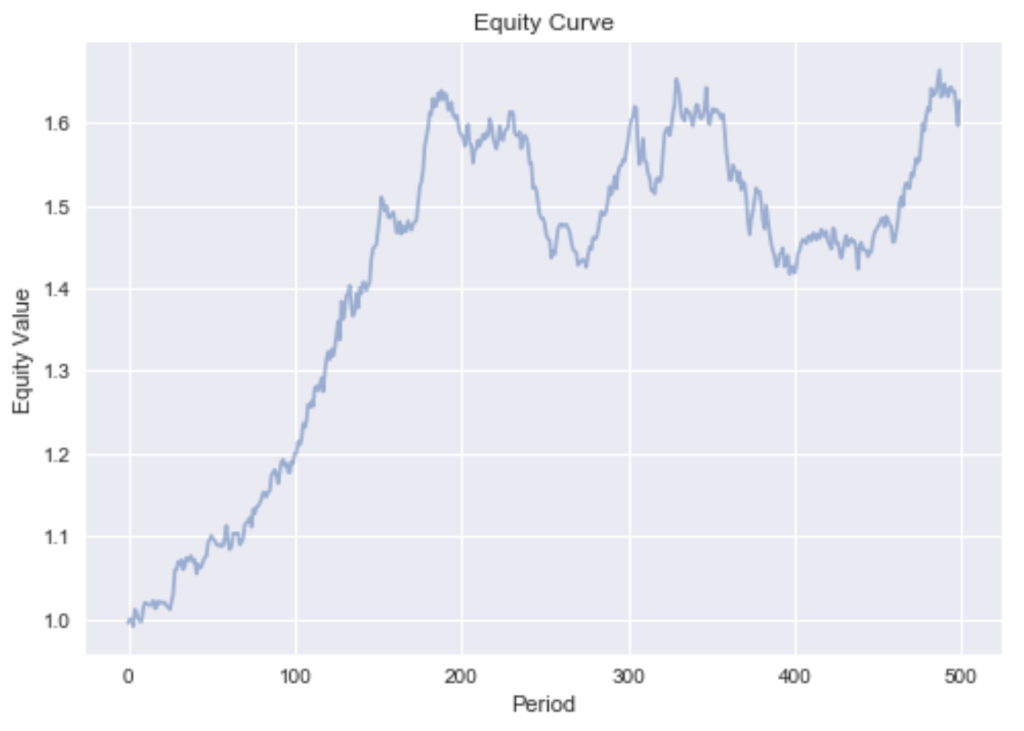
As an example, Figure 1 shows sample paths of 100 stocks belonging to the same industry.

Every stock’s return in this universe is partly driven by the market return (in proportion to its
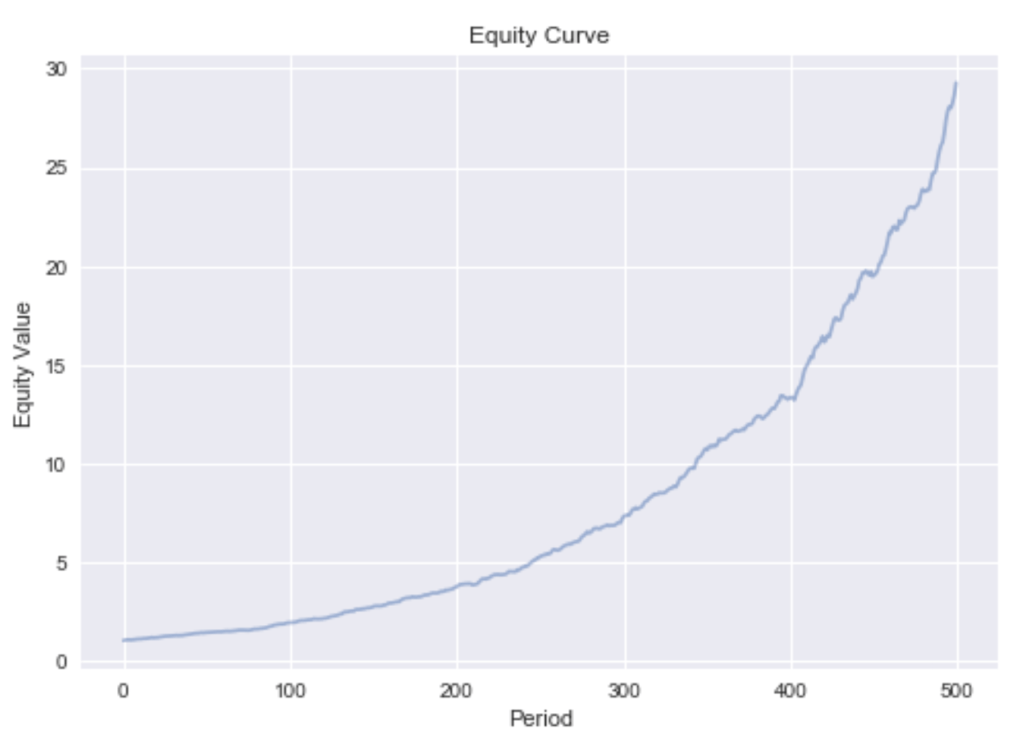
This very smooth equity curve can be achieved since we can hedge out the systematic factor risk. This makes our bets independent. Independence allows us to reason by the weak law of large numbers that the realized returns will converge in probability to the expected returns. This is only true if short sales are permitted. If we exclude shorting, we can only reduce the asset specific risk while exposing the portfolio to the irreducible systematic risk. The devastating effect this has on our portfolio can be seen by the much more rugged equity curve in Figure 3.
Hierarchical Optimization
In reality there isn’t just one industry but many. In the following, I will simulate a universe of stocks belonging to nine different industries. The corresponding sample paths are depicted in Figure 4.
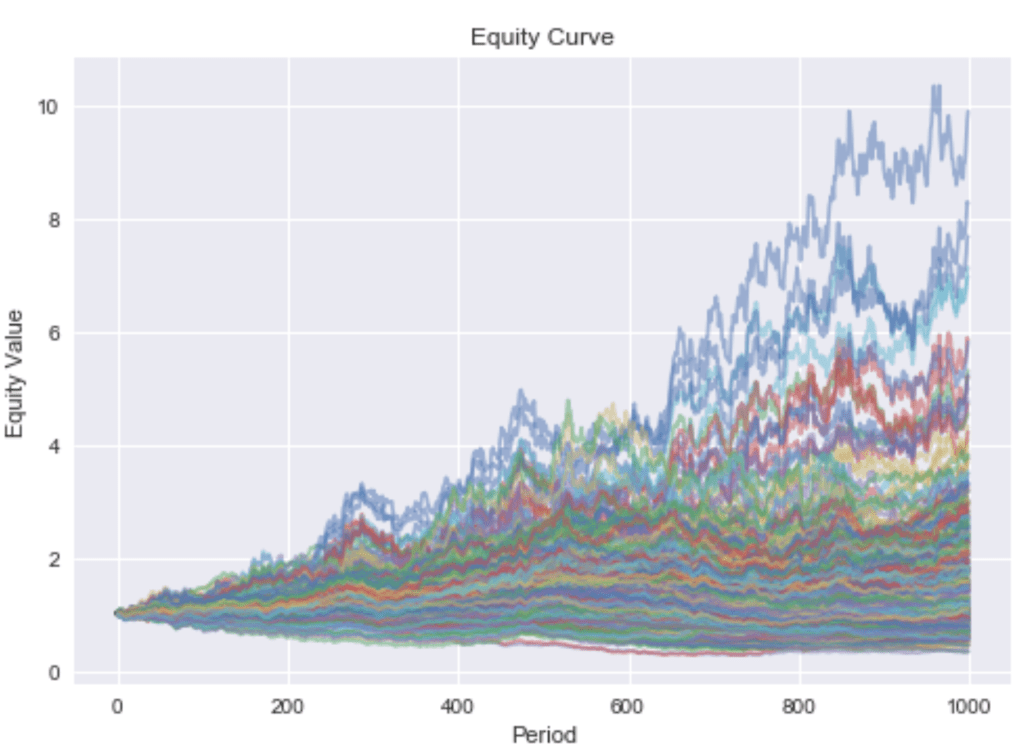
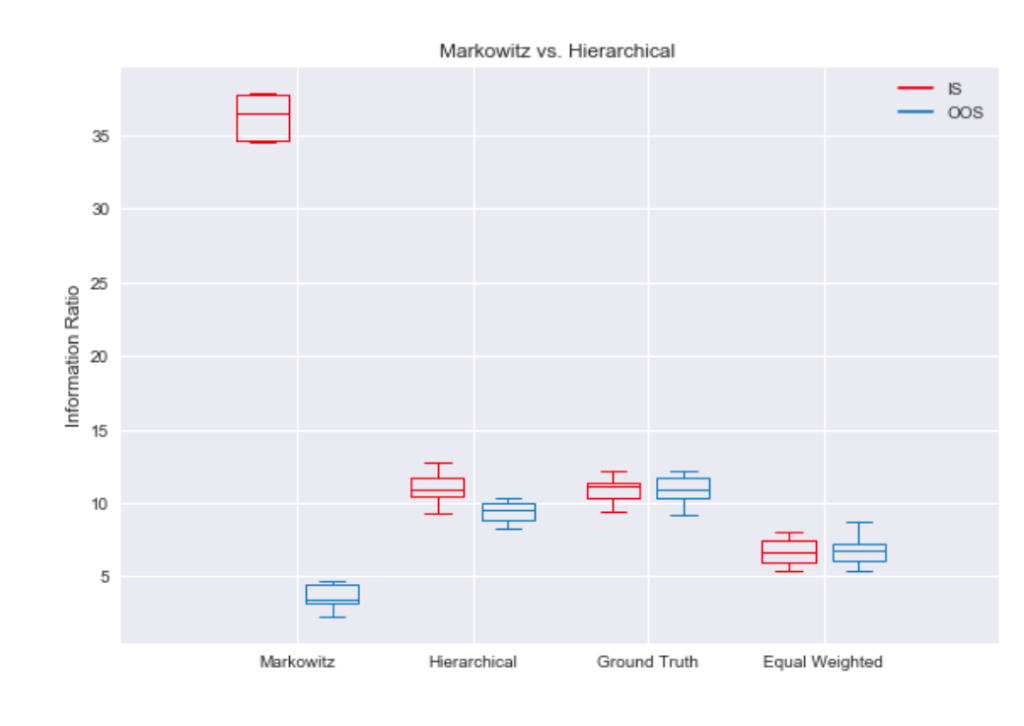
Now, all stocks are still partly driven by the market, but industry returns are uncorrelated. Estimation errors may cause problems if one stock is falsely used as a hedging device for the industry exposure of another stock, and both stocks do not belong to the same industry. The overfit of Markowitz’s method to in-sample data can best be visualized by a boxplot. Figure 5 shows that the in-sample information ratio for the sample covariance optimization is way above the best possible portfolio using ground truth parameters. Unsurprisingly, this overfit hurts the out-of-sample performance, as it can’t even beat simple equal weighting.

If we believe the above characterization of the problem is correct, it seems like a good idea to encode prior knowledge of industry clustering by optimize weights within clusters and then optimize allocation to these clusters. This hierarchical approach results in the in-sample and out-of-sample performance being much closer to the ground truth. Imposing structure, mean-variance optimization now beats equal weighting by a large margin.
Principal Component Analysis
Principal Component Analysis (PCA) allows us to reduce the rank of the covariance matrix. Since the covariance matrix is symmetric positive definite, we can, due to the spectral theorem, decompose the matrix into its real eigenvalues and orthonormal eigenvectors.

In the simulation we have exposure to the market and several industries. Thus, it makes sense to reduce the rank to the number of these variables. Plotting the proportion of variance explained by the first 

Decomposing the covariance matrix into its eigenvalues and eigenvectors, we can de-noise it by eliminating all eigenvalues below some threshold. Since the sample covariance matrix is positive definite, all its eigenvalues will be positive. Reconstructing a matrix from non-negative eigenvalues will likewise result in a positive semi-definite matrix. We thus don’t have to worry about the resulting matrix not being a proper covariance matrix, which can be a headache with more flexible estimation approaches. A heatmap of the reconstructed covariance matrix from the largest 10 eigenvalues is shown in Figure 7.

This covariance matrix looks very similar to the sample covariance matrix shown in Figure 8, despite having only a rank of 10. We can infer that it captures the important linear relationships between assets with less noise.

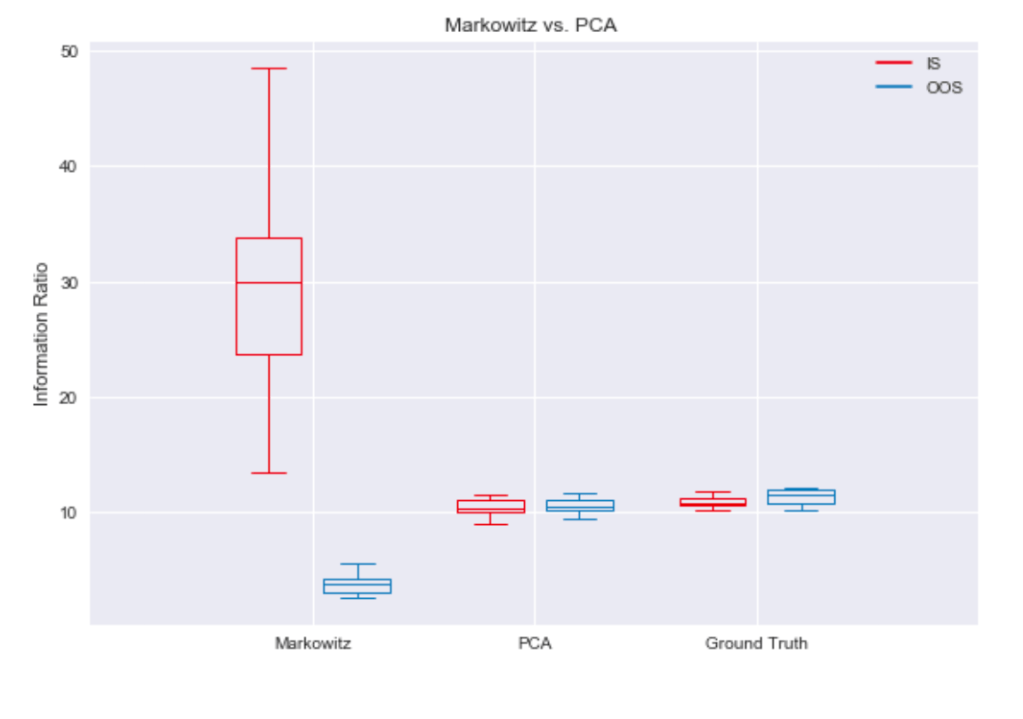
Observing the information ratios depicted in Figure 9, the PCA de-noising method seems capable of restricting factor hedging attempts to reasonable candidates. It beats mean-variance optimization based on the sample covariance matrix in out-of-sample data by a large margin.

Robustness under heavy tailed distributions
Until now, we’ve assumed Gaussian returns. It is a well known fact, though, that real stock return distributions are not Gaussian but heavy tailed. In the following, we will look at simulation results when asset specific noise is modeled by a GARCH process.
Asset specific noise, 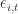
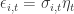
where
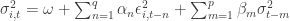

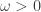




The unconditional variance of asset

which, when solved for 

I use this result to compute the ground truth covariance matrix. Sample paths according to a GARCH(1,1) data generating process are shown in Figure 10.
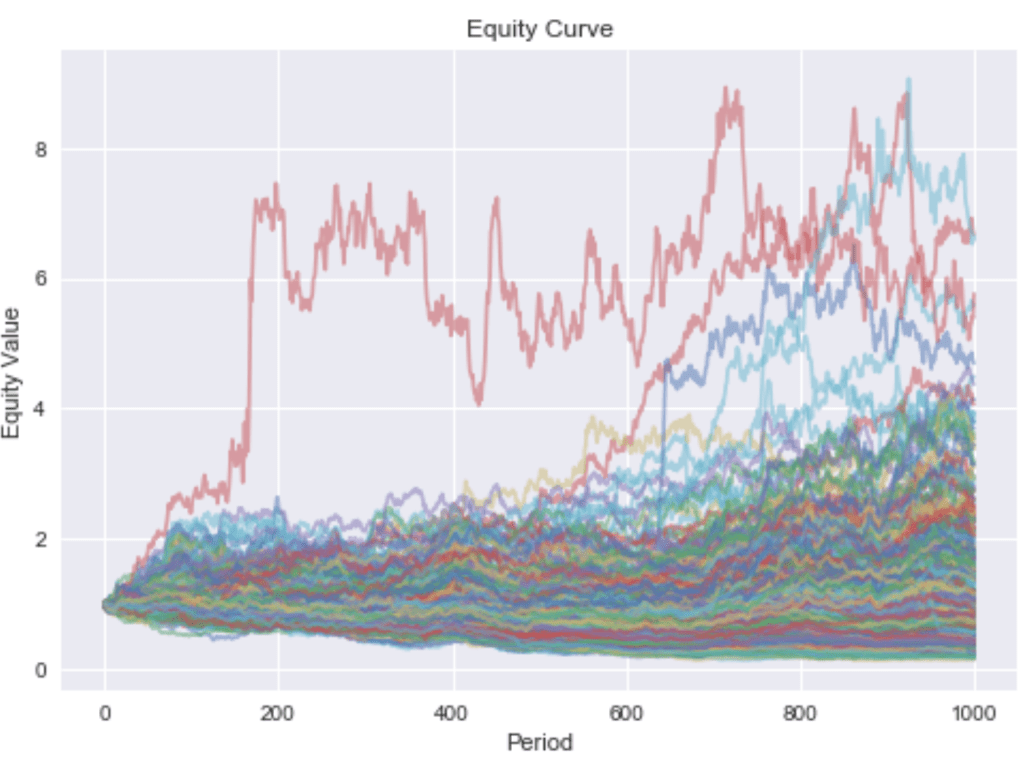
It’s easy to see that returns are much more extreme than under Gaussian noise. Since Markowitz’s mean-variance optimization tends to over-concentrate and thus expose the portfolio to asset specific risks, which are now heavy tailed, it performs even worse than in the Gaussian case. As shown in Figure 11, the hierarchical method still outperforms equal weighting.
Noise filtering by PCA results in portfolio performances near the ground truth, as can be seen in Figure 12.
Conclusion
To maximize risk-adjusted returns, it is necessary to hedge out systematic risk. How this hedging is done is the subject of portfolio optimization. We’ve seen that it’s important to regularize portfolio optimization, since estimation errors of the covariance matrix would otherwise push out-of-sample performance below that of naive approaches. How to achieve the regularization is a research topic all on its own. We’ve seen two approaches that can be developed far beyond the basics shown here. In addition, correlations between assets tend to be non-stationary. This fact needs to be respected as well. Furthermore, asset returns are driven by multiple factors and business models spread further into sub-clusters within industries. Larger corporations may also belong to multiple clusters. There’s so much more to learn. The code of the simulation, every plot shown here, and all the methods used to compute the portfolio weights is available at https://github.com/jpwoeltjen/OptimizePortfolio.
References
DeMiguel, Victor, Lorenzo Garlappi, and Raman Uppal. “Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy?.” The review of Financial studies 22.5 (2007): 1915-1953.
Markowitz, Harry. “Portfolio selection.” The journal of finance 7.1 (1952): 77-91.
